6.3.- El diseño 2^3
Suponga que tres factores, 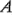 ,
, 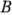 y
y  , cada uno con dos niveles, son de interés. Al diseño se le llama diseño factorial
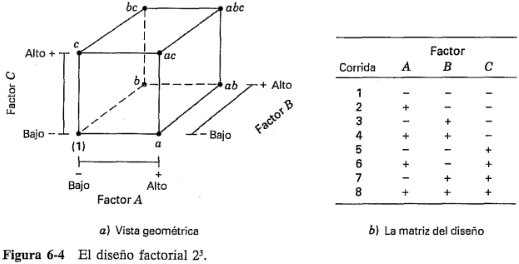
, cada uno con dos niveles, son de interés. Al diseño se le llama diseño factorial 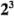 , y en este caso la representación geométrica de las ocho combinaciones de tratamientos puede hacerse con un cubo, como se muestra en la figura
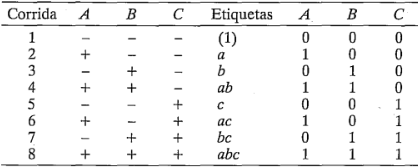
, y en este caso la representación geométrica de las ocho combinaciones de tratamientos puede hacerse con un cubo, como se muestra en la figura 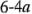 . Utilizando la notación"+" y "-" para representar los niveles alto y bajo de los factores, las ocho corridas del diseño
. Utilizando la notación"+" y "-" para representar los niveles alto y bajo de los factores, las ocho corridas del diseño 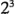 pueden enlistarse como en la figura
pueden enlistarse como en la figura 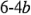 . Se le conoce en ocasiones como la matriz del diseño. Haciendo una ampliación de la notación de las etiquetas revisadas en la sección 6-2, las combinaciones de los tratamientos en el orden estándar se escriben como (1),
. Se le conoce en ocasiones como la matriz del diseño. Haciendo una ampliación de la notación de las etiquetas revisadas en la sección 6-2, las combinaciones de los tratamientos en el orden estándar se escriben como (1), 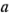 ,
, 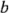 ,
, 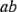 ,
, 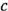 ,
, 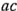 ,
, 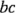 y
y 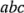 . Recuerde que estos símbolos representan también el total de las
. Recuerde que estos símbolos representan también el total de las  observaciones hechas con esa combinación de tratamientos particular.
observaciones hechas con esa combinación de tratamientos particular.
Existen en realidad tres notaciones diferentes para las corridas del diseño 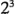 que son de uso general. La primera es la notación + y -, llamada con frecuencia notación geométrica. La segunda es el uso de las etiquetas en letras minúsculas para identificar las combinaciones de los tratamientos. La tercera y última notación utiliza 1 y 0 para denotar los niveles alto y bajo, respectivamente, de los factores, en lugar de + y -. Estas diferentes notaciones se ilustran enseguida para el diseño
que son de uso general. La primera es la notación + y -, llamada con frecuencia notación geométrica. La segunda es el uso de las etiquetas en letras minúsculas para identificar las combinaciones de los tratamientos. La tercera y última notación utiliza 1 y 0 para denotar los niveles alto y bajo, respectivamente, de los factores, en lugar de + y -. Estas diferentes notaciones se ilustran enseguida para el diseño 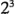 :
:
Hay siete grados de libertad entre las ocho combinaciones de tratamientos del diseño . Tres grados de libertad se asocian con los efectos principales de  ,
,  y
y  . Cuatro grados de libertad se asocian con las interacciones; uno con cada una de las interacciones , y y uno con la interacción .
. Cuatro grados de libertad se asocian con las interacciones; uno con cada una de las interacciones , y y uno con la interacción .
Considere la estimación de los efectos principales. Primero, considere la estimación del efecto principal . El efecto de cuando y están en el nivel bajo es 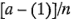 . De manera similar, el efecto de cuando está en el nivel alto y está en el nivel bajo es
. De manera similar, el efecto de cuando está en el nivel alto y está en el nivel bajo es 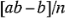 . El efecto de cuando está en el nivel alto y está en el nivel bajo es
. El efecto de cuando está en el nivel alto y está en el nivel bajo es 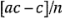 . Por último, el efecto de es sólo el promedio de estos cuatro efectos, o:
. Por último, el efecto de es sólo el promedio de estos cuatro efectos, o:
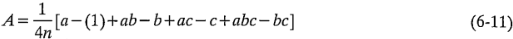
Esta ecuación también puede desarrollarse como un contraste entre las cuatro combinaciones de tratamientos de la cara derecha del cubo de la figura 6-5a (donde está en el nivel alto) y las cuatro de la cara izquierda (donde está en el nivel bajo). Es decir, el efecto de es sólo el promedio de las cuatro corridas donde está en el nivel alto 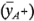 menos el promedio de las cuatro corridas donde está en el nivel bajo
menos el promedio de las cuatro corridas donde está en el nivel bajo 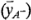 , o:
, o:
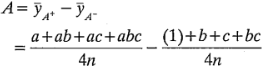
Esta ecuación puede reescribirse como: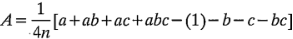
que es idéntica a la ecuación 6-11.
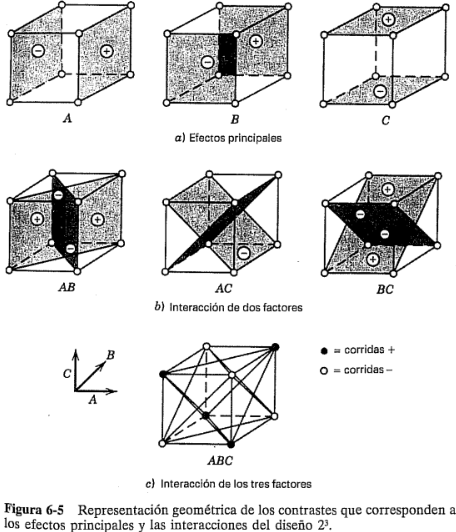
De manera similar, el efecto de es la diferencia en los promedios entre las cuatro combinaciones de tratamientos de la cara frontal del cubo y las cuatro de la cara posterior. Se obtiene así:
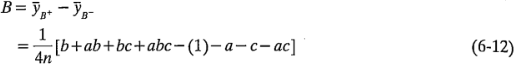
El efecto de es la diferencia en los promedios entre las cuatro combinaciones de tratamientos de la cara superior del cubo y las cuatro de la cara inferior, es decir,
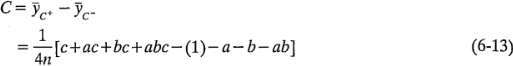
Los efectos de la interacción de dos factores pueden calcularse con facilidad. Una medida de la interacción 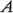 es la diferencia entre los efectos promedio de con los dos niveles de B. Por convención, a la mitad de esta diferencia se le llama la interacción . Utilizando símbolos,
es la diferencia entre los efectos promedio de con los dos niveles de B. Por convención, a la mitad de esta diferencia se le llama la interacción . Utilizando símbolos,

Puesto que la interacción es la mitad de esta diferencia,
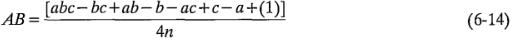
La ecuación 6-14 puede escribirse de la siguiente manera:
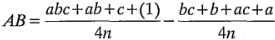
En esta forma, resulta fácil ver que la interacción es la diferencia en los promedios entre las corridas de dos planos diagonales del cubo de la figura 6-5b. Utilizando un razonamiento lógico similar y con referencia a la figura 6-5b, las interacciones y son:
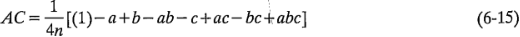
y
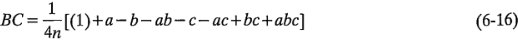
La interacción se define como la diferencia promedio entre la interacción para los dos diferentes niveles de . Por lo tanto,
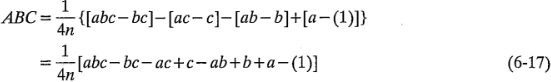
Como antes, la interacción puede considerarse como la diferencia de dos promedios. Si se aíslan las corridas de los dos promedios, éstas definen los vértices de los dos tetraedros que componen el cubo de la figura 6-5c.
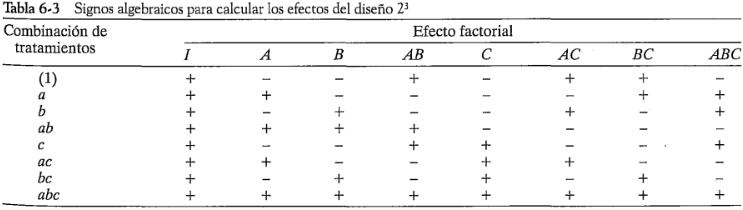
En las ecuaciones 6-11 a 6-17, las cantidades entre corchetes son contrastes de las combinaciones de los tratamientos. Es posible desarrollar una tabla de signos positivos y negativos a partir de los contrastes, la cual se muestra en la tabla 6-3. Los signos de los efectos principales se determinan asociando un signo positivo con el nivel alto y un signo negativo con el nivel bajo. Una vez que se han establecido los signos de los efectos principales, los signos de las columnas restantes pueden obtenerse multiplicando las columnas precedentes apropiadas, renglón por renglón. Por ejemplo, los signos de la columna son el producto de los signos de la columna y la columna en cada renglón. El contraste de cualquier efecto puede obtenerse fácilmente con esta tabla.
La tabla 6-3 tiene varias propiedades interesantes: 1) Con excepción de la columna I, cada una de las columnas tienen el mismo número de signos positivos y negativos. 2) La suma de los productos de los signos de dos columnas cualesquiera es cero. 3) La columna I multiplicada por cualquiera de las columnas deja la columna sin cambio. Es decir, I es un elemento identidad. 4) El producto de dos columnas cualesquiera produce una columna de la tabla. Por ejemplo, x = , y
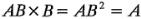
Se observa que los exponentes de los productos se forman utilizando la aritmética módulo 2. (Es decir, el. exponente sólo puede ser 0 o 1; si es mayor que 1, se reduce con múltiplos de 2 hasta que es 0 o 1.) Todas estas propiedades se derivan de la ortogonalidad de los contrastes usados para estimar los efectos. Las sumas de cuadrados de los efectos se calculan con facilidad, ya que cada efecto tiene un contraste correspondiente con un solo grado de libertad. En el diseño con 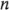 réplicas, la suma de cuadrados de cualquier efecto es:
réplicas, la suma de cuadrados de cualquier efecto es:

El modelo de regresión y la superficie de respuesta
El modelo de regresión para predecir la desviación de la altura de llenado es:
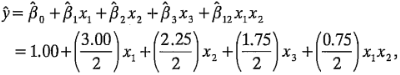
donde las variables codificadas 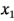 ,
, 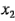 y
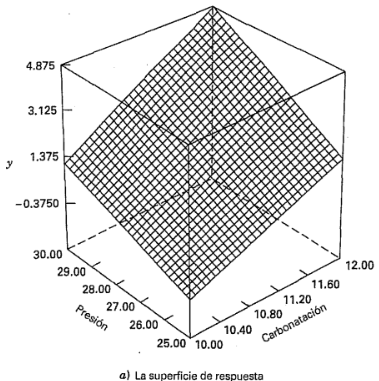
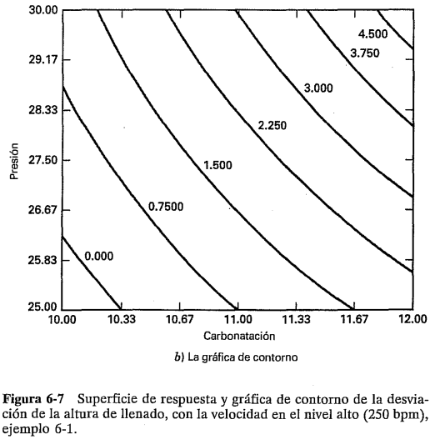
y 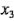 representan a , y , respectivamente. El término es la interacción . Los residuales pueden obtenerse como la diferencia entre las desviaciones de la altura de llenado observada y la predicha. El análisis de estos residuales se deja como ejercicio para el lector. En la figura 6-7 se muestra la superficie de respuesta y la gráfica de contorno para la desviación de la altura de llenado obtenida con el modelo de regresión, suponiendo que la velocidad de línea está en el nivel alto
representan a , y , respectivamente. El término es la interacción . Los residuales pueden obtenerse como la diferencia entre las desviaciones de la altura de llenado observada y la predicha. El análisis de estos residuales se deja como ejercicio para el lector. En la figura 6-7 se muestra la superficie de respuesta y la gráfica de contorno para la desviación de la altura de llenado obtenida con el modelo de regresión, suponiendo que la velocidad de línea está en el nivel alto 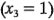 . Observe que como el modelo contiene la interacción, las líneas de contorno de la desviación de las alturas de llenado constantes son curvas (o la superficie de respuesta es un plano "torcido"). Es deseable operar este proceso de llenado de tal modo que la desviación del llenado esté tan cerca de cero como sea posible. La gráfica de contorno indica que, si la velocidad de línea está en el nivel alto, entonces hay varias combinaciones de los niveles de la carbonatación y la presión que satisfarán este objetivo. Sin embargo, será necesario ejercer un control preciso de estas dos variables.
. Observe que como el modelo contiene la interacción, las líneas de contorno de la desviación de las alturas de llenado constantes son curvas (o la superficie de respuesta es un plano "torcido"). Es deseable operar este proceso de llenado de tal modo que la desviación del llenado esté tan cerca de cero como sea posible. La gráfica de contorno indica que, si la velocidad de línea está en el nivel alto, entonces hay varias combinaciones de los niveles de la carbonatación y la presión que satisfarán este objetivo. Sin embargo, será necesario ejercer un control preciso de estas dos variables.
Solución por computadora
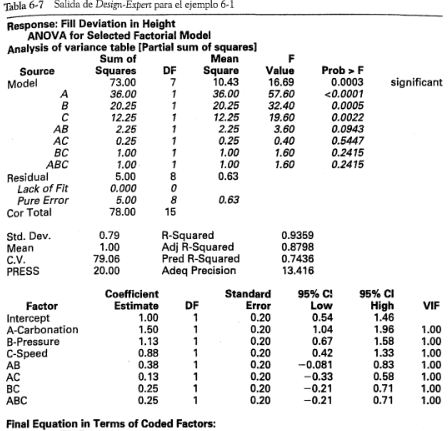
Hay muchos paquetes de software de estadística que establecerán y analizarán diseños factoriales con dos niveles. La salida de uno de estos programas de computadora, Design-Expert, se muestra en la tabla 6-7. En la parte superior de la tabla se presenta el análisis de varianza del modelo completo. El formato de esta presentación es un tanto diferente de los resultados dados en la tabla 6-6. Observe que el primer renglón del análisis de varianza es un resumen global del modelo completo (todos los efectos principales y las interacciones), y la suma de cuadrados del modelo es:
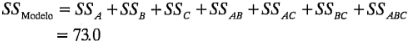
Por lo tanto, el estadístico
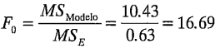
está probando las hipótesis

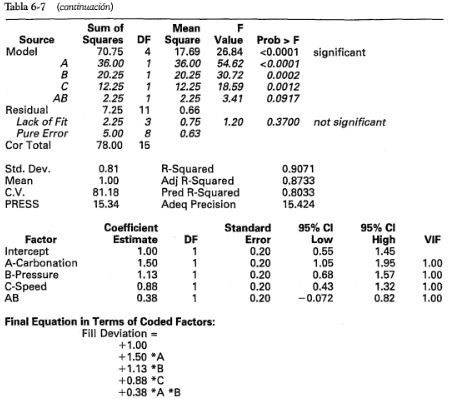
Puesto que  es grande, se concluiría que al menos una de las variables tiene un efecto diferente de cero. Entonces se prueba la significación de cada efecto factorial individual utilizando el estadístico
es grande, se concluiría que al menos una de las variables tiene un efecto diferente de cero. Entonces se prueba la significación de cada efecto factorial individual utilizando el estadístico  . Estos resultados concuerdan con la tabla 6-6.
. Estos resultados concuerdan con la tabla 6-6.
Abajo del análisis de varianza del modelo completo se presentan varios estadísticos 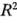 . La
. La 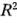 ordinaria es:
ordinaria es:
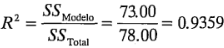
y mide la proporción de la variabilidad total explicada por el modelo. Un problema potencial con este estadístico es que siempre se incrementa cuando se agregan factores al modelo, incluso cuando estos factores no son significativos. El estadístico ajustada, definido como:
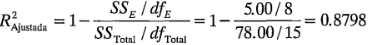
es un estadístico que está ajustado para el "tamaño" del modelo; es decir, para el número de factores. La ajustada puede decrecer en realidad si se agregan términos no significativos al modelo. El estadístico PRESS es una medida de qué tan bien predecirá datos nuevos el modelo (PRESS es en realidad el acrónimo de Prediction Error Sum of Squares-suma de cuadrados del error de predicción-, y se calcula a partir de los errores de predicción obtenidos al predecir el punto i-ésimo de los datos con un modelo que incluye todas las observaciones, excepto la i-ésima). Un modelo con un valor pequeño de PRESS indica que es posible que el modelo sea un buen predictor. El estadístico " de predicción" se calcula como:
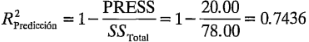
Esto indica que se esperaría que el modelo completo explique cerca de 74% de la variabilidad de los datos nuevos.
La siguiente sección de la salida presenta el coeficiente de regresión de cada término del modelo y el error estándar (se, standard error) de cada coeficiente, definido como:
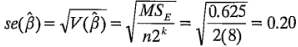
Los intervalos de confianza de 95% para cada coeficiente de regresión se calculan a partir de: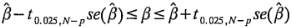
donde los grados de libertad de t es el número de grados de libertad del error; es decir, 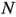 es el número total de corridas en el experimento (16), y
es el número total de corridas en el experimento (16), y 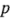 es el número de parámetros del modelo (8). También se presenta el modelo completo en términos de las variables codificadas y de las variables naturales.
es el número de parámetros del modelo (8). También se presenta el modelo completo en términos de las variables codificadas y de las variables naturales.
En la última sección de la tabla 6-7 se ilustra la salida después de eliminarlos términos de las interacciones no significativas. Este modelo reducido contiene ahora sólo los efectos principales , y , y la interacción . La suma de cuadrados de los residuales o del error se compone ahora de un componente del error puro ("Pure Error") que surge de las réplicas de los ocho vértices del cubo, y un componente de falta de ajuste ("Lack of Fit"), compuesto por las sumas de cuadrados de las interacciones que se eliminaron del modelo (, y ). De nueva cuenta, la representación del modelo de regresión de los resultados experimentales se presenta en términos de las variables codificadas y las variables naturales. La proporción de la variabilidad total de la desviación de la altura del llenado que se explica por este modelo es:
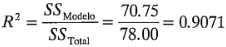
que es menor que la del modelo completo. Observe, sin embargo, que la ajustada del modelo reducido apenas ha cambiado ligeramente respecto de la ajustada del modelo completo, y PRESS del modelo reducido es considerablemente menor, lo cual produce un valor más grande de  del modelo reducido. Evidentemente, la eliminación de los términos no significativos del modelo completo ha producido un modelo final que posiblemente funcionará con mayor eficiencia como predictor de datos nuevos. Observe que los intervalos de confianza para los coeficientes de regresión del modelo reducido son ligeramente más cortos que los intervalos de confianza correspondientes en el modelo completo. En la última sección de la salida se presentan los residuales del modelo reducido. Design-Expert también construirá todas las gráficas de los residuales que se estudiaron anteriormente.
del modelo reducido. Evidentemente, la eliminación de los términos no significativos del modelo completo ha producido un modelo final que posiblemente funcionará con mayor eficiencia como predictor de datos nuevos. Observe que los intervalos de confianza para los coeficientes de regresión del modelo reducido son ligeramente más cortos que los intervalos de confianza correspondientes en el modelo completo. En la última sección de la salida se presentan los residuales del modelo reducido. Design-Expert también construirá todas las gráficas de los residuales que se estudiaron anteriormente.
Otros métodos para evaluar la significación de los efectos
El análisis de varianza es una manera formal de determinar cuáles son los efectos de los factores que son diferentes de cero. Existen varios métodos más que son útiles. A continuación, se indica cómo calcular el error estándar de los efectos y cómo usar los errores estándar para construir intervalos de confianza para los efectos. Otro método, que se ilustrará en la sección 6-5, utiliza gráficas de probabilidad normal para valorar la importancia de los efectos.
Es sencillo encontrar el error estándar de un efecto. Si se supone que hay réplicas en cada una de las  corridas del diseño, y si
corridas del diseño, y si 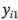 ,
, 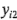 , ...,
, ..., 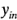 son las observaciones de la corrida i-ésima, entonces:
son las observaciones de la corrida i-ésima, entonces:
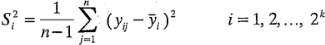
es una estimación de la varianza de la corrida i-ésima. Las estimaciones de la varianza del diseño pueden combinarse para dar una estimación de la varianza global:
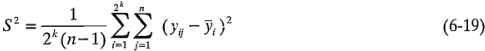
Ésta es también la estimación de la varianza dada por el cuadrado medio del error en el análisis de varianza. La varianza de la estimación de cada efecto es:
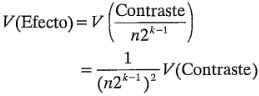
Cada contraste es una combinación lineal de los totales de los tratamientos, y cada total consta de observaciones. Por lo tanto:
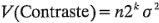
y la varianza de un efecto es:
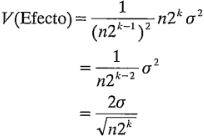
El error estándar estimado se encontraría sacando la raíz cuadrada de esta última expresión y sustituyendo 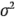 con su estimación
con su estimación 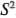 :
:

Observe que el error estándar de un efecto es el doble del error estándar de un coeficiente de regresión estimado en el modelo de regresión del diseño (ver la salida de computadora de Design-Expert del ejemplo 6-1).
Los intervalos de confianza de 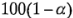 por ciento para los efectos se calculan a partir de Efecto ±
por ciento para los efectos se calculan a partir de Efecto ±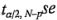 (Efecto), donde los grados de libertad de t son sólo los grados de libertad de los residuales o del error (
(Efecto), donde los grados de libertad de t son sólo los grados de libertad de los residuales o del error (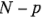 = número total de corridas - número de parámetros del modelo).
= número total de corridas - número de parámetros del modelo).
Para ilustrar este método, considere el experimento de la desviación de la altura de llenado del ejemplo 6-1. El cuadrado medio del error es 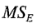 =0.625. Por lo tanto, el error estándar de cada efecto es (utilizando =
=0.625. Por lo tanto, el error estándar de cada efecto es (utilizando =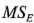 )
)

Entonces, 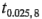 =2.31 y
=2.31 y 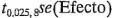 =2.31(0.40) =0.92, de donde los intervalos de confianza de 95% aproximados para los efectos de los factores son:
=2.31(0.40) =0.92, de donde los intervalos de confianza de 95% aproximados para los efectos de los factores son:

Este análisis indica que , y son factores importantes, porque son las únicas estimaciones de los efectos de los factores para las que los intervalos de confianza de 95% aproximados no incluyen al cero.
Efectos de dispersión
El ingeniero de proceso que trabajó en el caso del llenado también se interesó en los efectos de dispersión; es decir, ¿alguno de los factores afecta la variabilidad de la desviación de la altura de llenado de una corrida a otra? Una manera de responder esta pregunta es examinando el rango de las desviaciones de la altura de llenado para cada una de las ocho corridas del diseño . Estos rangos se grafican en el cubo de la figura 6-8. Observe que los rangos son aproximadamente iguales para las ocho corridas del diseño. Por consiguiente, no hay evidencia sólida que indique que alguna de las variables del proceso afecte directamente la variabilidad de la desviación de la altura de llenado en el proceso.
Última modificación: martes, 20 de febrero de 2024, 14:01