10.7.1.- Residuales Escalados y PRESS
Residuales estandarizados y studentizados
Muchos constructores de modelos prefieren trabajar con residuales escalados en lugar de los residuales de mínimos cuadrados ordinarios. Estos residuales escalados transmiten con frecuencia más información que los residuales ordinarios.
Un tipo de residual escalado es el residual estandarizado:

donde por lo general se usa σ = √(MSE) en los cálculos. Estos residuales estandarizados tienen media cero y varianza aproximadamente unitaria; por consiguiente, son muy útiles para buscar puntos atípicos. La mayoría de los residuales estandarizados deberán localizarse en el intervalo -3 ≤ di ≤ 3, y cualquier observación con un residual estandarizado que esté fuera de este intervalo es potencialmente inusual con respecto a su respuesta observada. Estos puntos atípicos deberán examinarse con atención, ya que pueden representar algo tan simple como un error al registrar los datos o algo que sea motivo de mayor preocupación, como una región del espacio del regresor, donde el modelo ajustado es una aproximación pobre de la verdadera superficie de respuesta.
El proceso de estandarización de la ecuación 10-43 escala los residuales al dividirlos por su desviación estándar promedio aproximada. En algunos conjuntos de datos, los residuales pueden tener desviaciones estándar que difieren considerablemente. A continuación se presenta una escalación que toma en consideración esta situación.
El vector de los valores ajustados y'i que corresponden a los valores observados yi es

A la matriz n x n, H = X(X'X)-1X' se le llama generalmente la matriz "gorro" porque mapea el vector de los valores observados en un vector de los valores ajustados. La matriz gorro y sus propiedades desempeñan un papel central en el análisis de regresión.
Los residuales del modelo ajustado pueden escribirse convenientemente en la notación matricial como
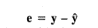
y resulta que la matriz de covarianza de los residuales es

La matriz I - H no es por lo general diagonal, por lo que los residuales tienen varianzas diferentes y están correlacionados.
Por lo tanto, la varianza del residual i-ésimo es

donde hii es el elemento i-ésimo de la diagonal de H. Puesto que 0 ≤ hii ≤ 1, al utilizar el cuadrado medio residual MSE para estimar la varianza de los residuales en realidad se está sobreestimando V(e¡). Además, puesto que hii es una medida de localización del punto i-ésimo en el espacio x, la varianza de e¡ depende de dónde esté el punto xi. En general, los residuales situados cerca del centro del espacio x tienen varianzas más grandes que los residuales situados en lugares más apartados. Las violaciones de los supuestos del modelo son más probables en los puntos remotos, y estas violaciones pueden ser difíciles de detectar por la inspección de e¡ (o d¡) porque sus residuales serán por lo general más pequeños.
Se recomienda tomar en consideración esta desigualdad de la varianza cuando se escalen los residuales. Se sugiere graficar los residuales studentizados:
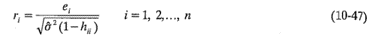
σ2 = MSE en lugar de e¡ (o d¡). Los residuales studentizados tienen varianza constante V(r¡) =1 independientemente de la localización de xi cuando la forma del modelo es correcta. En muchas situacionesla varianza de los residuales se estabiliza, en particular para conjuntos de datos grandes. En estos casos puede haber poca diferencia entre los residuales estandarizados y los studentizados. Por lo tanto, los residuales estandarizados y studentizados transmiten con frecuencia información equivalente. Sin embargo, ya que cualquier punto con un residual grande y una hii grande tiene una influencia potencialmente considerable sobre el ajuste de mínimos cuadrados, suele recomendarse el examen de los residuales studentizados. En la tabla 10-3 se presentan las diagonales gorro hii y los residuales studentizados para el modelo de regresión de la viscosidad del ejemplo 10-1.
Residuales PRESS
La suma de cuadrados del error de predicción (PRESS, del inglés Prediction Error Sum of Squares) proporciona una útil escalación de los residuales. Para calcular la PRESS se selecciona una observación, por ejemplo la i. Se ajusta el modelo de regresión a las n - 1 observaciones restantes y se usa esta ecuación para predecir la observación que se apartó yi, Al denotar este valor predicho y'(i), puede encontrarse el error de predicción del punto i como e(i) = yi = y'(i), Al error de predicción suele llamársele el residual PRESS i-ésimo. Este procedimiento se repite para cada observación i = 1, 2, ...,n, produciéndose un conjunto de n residuales PRESS e(1), e(2), ..., e(n). Entonces el estadístico PRESS se define como la suma de cuadrados de los n residuales PRESS como en
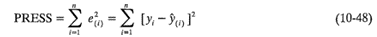
Por lo tanto, la PRESS utiliza cada subconjunto posible de n -1 observaciones como un conjunto de datos de estimación, y se utiliza una observación a la vez para formar un conjunto de datos de predicción.
Inicialmente, parecería que para calcular la PRESS es necesario ajustar n regresiones diferentes. Sin embargo, la PRESS puede calcularse a partir de los resultados de un solo ajuste de mínimos cuadrados a las n observaciones totales. Resulta que el residual PRESS i-ésimo es

Por lo tanto, ya que la PRESS es tan sólo la suma de cuadrados de los residuales PRESS, una fórmula de cálculo simple es

Por la ecuación 10-49 es sencillo ver que el residual PRESS es sólo el residual ordinario ponderado de acuerdo con los elementos de la diagonal de la matriz gorro hii. Los puntos de los datos para los que hii es grande tendrán residuales PRESS grandes. Estas observaciones serán por lo general puntos de alta influencia. En general, una diferencia grande entre el residual ordinario y los residuales PRESS indicará un punto donde el modelo se ajusta bien a los datos, pero un modelo construido sin dicho punto producirá predicciones pobres. En la siguiente sección se estudiarán otras medidas de influencia.
Por último, cabe señalar que la PRESS puede usarse para calcular una R2 aproximada de predicción, por ejemplo

Este estadístico ofrece cierto indicio de la capacidad predictiva del modelo de regresión. Para el modelo de regresión de la viscosidad del ejemplo 10-1, los residuales PRESS pueden calcularse utilizando los residuales ordinarios y el valor de hii encontrado en la tabla 10-3. El valor correspondiente del estadístico PRESS es PRESS = 5207.7. Entonces
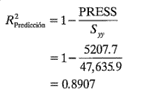
Por lo tanto, podría esperarse que este modelo "explique" cerca de 89% de la variabilidad al predecir nuevas observaciones, en comparación con el aproximadamente 93% de la variabilidad en los datos originales que explica el ajuste de mínimos cuadrados. La capacidad predictiva global del modelo basado en este criterio parece ser muy satisfactoria.
R-student
Es común considerar al residual studentizado r¡ comentado antes como el diagnóstico de un punto atípico. Se acostumbra usar MSE como una estimación de σ2 en el cálculo de r¡. Se hace referencia a este enfoque como la escalación interna del residual, ya que MSE es una estimación de σ2 generada internamente que se obtiene del ajuste del modelo a las n observaciones. Otro enfoque sería usar una estimación de σ2 basada en un conjunto de datos en el que se elimina la observación i-ésima. La estimación de σ2 así obtenida se denota por S2(i). Puede demostrarse que
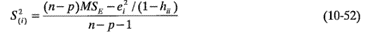
La estimación de σ2 de la ecuación 10-52 se usa en lugar de MSE para producir un residual studentizado externamente, al que es común llamar R-student, dado por
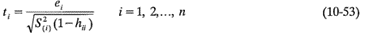
En muchas situaciones habrá una ligera diferencia entre t¡ y el residual studentizado r¡. Sin embargo, si la observación i-ésima es influyente, entonces S2(i) puede diferir significativamente de MSE, y por lo tanto la R-student será más sensible a este punto. Además, bajo los supuestos usuales, t¡ tiene una distribución tn-p-1. Por lo tanto, la R-student ofrece un procedimiento más formal para detectar puntos atípicos a través de la prueba de hipótesis. En la tabla 10-3 se muestran los valores de laR-student para el modelo de regresión de la viscosidad del ejemplo 10-1. Ninguno de esos valores es inusualmente grande.
Última modificación: domingo, 17 de marzo de 2024, 22:24